
What "Quantization Constants" and "Double Quantization" actually mean?

Intro
Let’s say you want to fine-tune your own LLM using QLoRA. You’ve probably already found a Colab notebook example/tutorial, adapted it to your use case, and things worked out just fine. If you are like me, however, you might want to understand the meaning behind the many parameters you’ve left at default along the way.
Today, we’ll look at Double Quantization and the associated notion of Quantization Constants. When trying to figure it out for the first time, I’ve had a fairly frustrating experience as most resources provided brief/unsatisfactory/circular explanations such as “quantization constants are created during quantization” and “double quantization is the process of quantizing quantization constants to save extra space”. While vaguely making sense, I could not understand what this meant exactly without reading the original QLoRA paper. This post will explain the concept directly.
So what is double quantization?
In simplest terms, yes, double quantization is “quantization of quantization constants”. But what are those quantization constants? The need for them arises because of a nuance in the “regular” quantization process.
Intuitively, LLM quantization means using a smaller number of bits to represent model weights. But if we naively cast high-bit numbers to a lower-bit type, it’d be a disaster.
As illustrated below, higher-bit data types usually have vastly larger ranges of acceptable values, e.g. 10^38 for float32 vs 10^15 for float16. If we use naive casting, all weight values outside the float16 range (highlighted in red in the image below) will be clipped to max/min float16 values, and we’d be losing a lot of information.
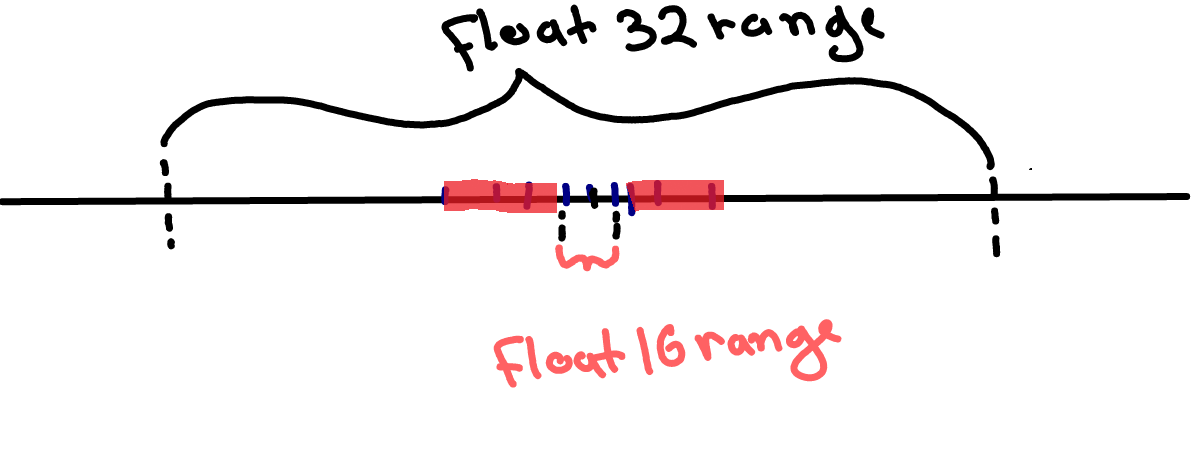
Note: the image above is not drawn to scale. Otherwise, float16 range would be a tiny dot less than one pixel wide.
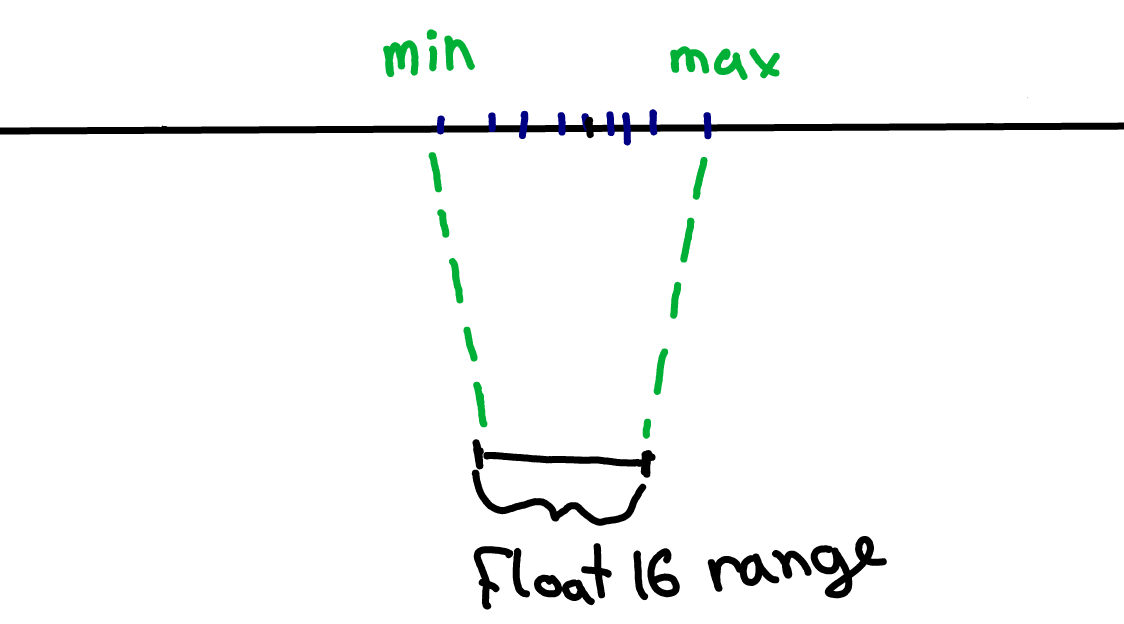
What we can do instead is look at the range of the weights in our model (blue marks on the image below), and map this range onto the full range of the lower-bit datatype. This way, we would only “stretch” the lower-precision datatype range over the relevant part of the higher-bit datatype range and we won’t need to clip anything.
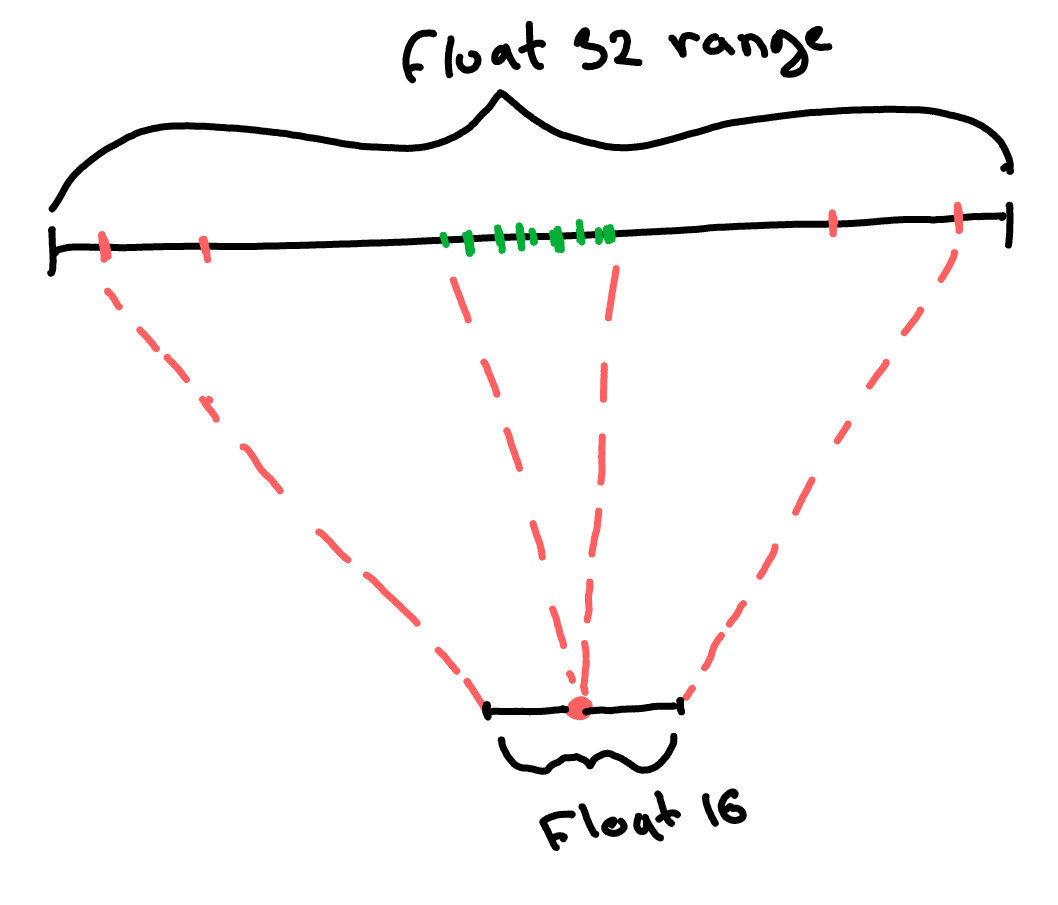
There is still, however, a problem. When we have billions of parameters, we are likely to get some outliers (red weights in the image below). So if we look at ALL the weights to determine the min/max weight values, we might end up mapping a large proportion of the float32 range into a tiny float16 range. In this case, most non-extreme weights (green) are going to essentially collapse onto a single point and become indistinguishable from one another after our transformation. This is, of course, terrible news, as we’d be losing a lot of information because of just a few outliers.
To combat that, what we can do is group all weights into smaller blocks and quantize each block independently. This way, each (rare) outlier will only affect the one small block it belongs to, instead of affecting all quantized weights. So this is good news. The bad news is that for each block of weights, we now need to store a separate “min” and “max” value. The totality of these values for all blocks is what we call “Quantization Constants”. In a large model, we end up with a lot of weight blocks, and all these quantization constants end up taking a non-negligible amount of space.
With this in mind, double quantization makes sense. We simply save space by storing these numerous quantization constants more efficiently (quantizing them using the same/similar process).
I hope this helps. Let me know if something is still confusing. Please share the post if you’ve found it helpful.
Disclaimer
There are many different quantization schemes and methods. In this post, I present a general intuition that applies to most quantization scenarios, but it’s not exhaustive, and the logic does not work when we quantize to, say, brain float 16 as the data type is already designed to have the same range as float32.
If you’d like to learn more about the process - the original QLoRA paper is a good starting point, but also - let me know, I’d be happy to write more posts about the topic!
Sources
QLoRA - it’s always good to read the original, especially if you are serious about LLM fine-tuning.
LLM.int8() - I’ve only discussed one aspect of dealing with outliers, but many other techniques are out there. This paper is a good place to start learning more.